Building Local RAG for Privacy Protection
- Jul 7, 2024
- 6 min read
Updated: Jun 17, 2025
In this blog post, we will review the concept of Retrieval-Augmented Generation (RAG) by exploring its applications and benefits. We will also examine a practical use case to highlight its significance in enhancing AI-driven solutions. We will build a local RAG which does not allow the leakage of our data to 3rd parties. For this use-case, we will restrict the employed models to a certain parameter range due to technical limitations.
📈 Discover how real businesses use AI to create value. Join the newsletter for practical use cases and strategic insights.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an advanced AI framework that combines the strengths of retrieval-based and generative models. This means that instead of relying solely on pre-trained knowledge, the AI can retrieve relevant information from external sources and integrate it into its responses.
This approach enhances the accuracy and relevance of the AI's output, making it particularly useful in complex tasks such as customer support, content creation, and research. Think of Retrieval-Augmented Generation (RAG) as AI with a "memory boost" feature. Imagine when you ask a knowledgeable friend a question, and they not only give you an answer but also pull out relevant references to support their response.
As we mentioned, RAG combines retrieval-based and generative models. The main functionality of the retrieval-based models is to search and retrieve information from a large database or corpus. They excel at fetching relevant documents or pieces of data in response to a query. Generative models are used to generate new content based on the input they receive. They create responses from scratch, using patterns they have learned during training. RAG leverages both retrieval-based and generative models to enhance AI's capabilities. It retrieves relevant information from external sources and uses generative models to integrate this information into accurate and contextually relevant responses.

RAG's process can be summarized in 4 simple steps: a) the AI system receives a query, b) this query is used to search the knowledge base for relevant information, c) the relevant information is fed to the LLM together with the query and d) the system outputs the model's response. It's the LLM's job to combine the retrieved information and generate a detailed and accurate response.
As you might have already understood, the critical step is not the 3rd but the 2nd. Many big tech giants are spending millions for researching and training LLMs to outperform competitors, which is good because we can select a LLM from a wide variety based on our requirements. What we need to do to have great results, is to be able to provide accurate relevant information together with our query to the LLM. We will review this process later on.
Why Use RAG?
The integration of retrieval mechanisms with generative models provides several advantages:
Enhanced Accuracy: By accessing up-to-date information, RAG ensures that responses are accurate and relevant.
Contextual Understanding: RAG can retrieve context-specific data, making the AI's responses more coherent and contextually appropriate.
Scalability: This approach allows AI systems to scale more effectively by leveraging vast external knowledge bases.
Potential use-cases
RAG is revolutionizing various industries by combining the power of retrieval-based and generative models. Let's review some use-cases of RAG across different sectors, showcasing its potential to transform industry practices and improve operational efficiency.
Customer Support: Enhances chatbot interactions by retrieving relevant data from customer databases and generating accurate, contextually appropriate responses.
Healthcare: Supports patient interactions by providing detailed explanations and answering queries with up-to-date medical knowledge.
Education: Assists educators in creating comprehensive lesson plans and resources by integrating up-to-date academic research and information.
Retail: Improves product recommendation systems by retrieving and integrating customer data and product information, generating personalized recommendations.
Finance: Aids financial analysts by retrieving market data, financial reports, and news articles, generating detailed financial analyses and reports.
Privacy Issues in Building RAG Online vs. Offline
The implementation of RAG systems involves several privacy considerations, especially when comparing online and offline setups.
Online RAG systems face privacy issues primarily related to data transmission, storage, user privacy, and regulatory compliance. Data must be transmitted over the internet, increasing the risk of interception, which can be mitigated with encryption protocols like HTTPS. External servers may store sensitive information, posing a risk if compromised, so it's crucial to use providers that comply with robust data protection standards.
These systems may also collect user data, risking privacy violations if mishandled; implementing data anonymization, minimization practices, and obtaining user consent are essential. Additionally, ensuring compliance with data protection regulations across different jurisdictions can be complex, necessitating regular reviews and updates of privacy policies.
On the other hand, offline RAG systems offer enhanced privacy by operating within a controlled environment, reducing external breach risks but requiring robust physical and network security measures to prevent internal breaches. Limited access to real-time external information can lead to outdated data, impacting accuracy, so regular updates and periodic syncing with online sources are necessary.
Use-case: Building RAG offline
To build a RAG system offline, one must consider their resources first and foremost. A large language model can easily occupy dozens of gigabytes of vRAM depending on its architecture and number of parameters. Gemma2 for example comes with 2 versions the 9B and 27B models. The 9B model consumes about 12GB of vRAM while the 27B about 24GB vRAM (both in their 4-bit quantized versions!).
The LLM is not the only deep learning model needed for the RAG architecture. As we mentioned, the 2nd step fetching the most relevant information from the knowledge base is crucial. To be able to fetch the relevant information from the knowledge base, we have to build the database from our data. To handle this task, we need to define the database for this task (vector database) and the mechanism that will transform our data/documents to such vectors.
A vector database stores and manages high-dimensional vector representations of data, which are essential in RAG for efficient and accurate similarity search and retrieval of relevant information. The mechanism for the vectorization can be implemented through Sentence embeddings. These embeddings are dense vector representations of sentences that capture their semantic meaning, crucial for tasks like text classification, clustering, and retrieval in natural language processing.
The employed GPU has only 16GB vRAM which means that the selection of the LLM, vector database, and Sentence embeddings have to be careful not to crash the system. For this reason, we have selected the following:
Sentence embeddings: Alibaba-NLP/gte-Qwen2-1.5B-instruct
Large language model: Gemma2, 9B/27B
Vector database: Chroma db
To deploy the LLM locally as a REST-API service, we use open-source libraries. As for the data, we have utilized a set of publicly available e-books in the domain of machine learning, deep learning, and business strategy. To vectorize the information in these PDFs, we have to tune the sentence embeddings to optimize the relevant information that will be fetched given our queries. A chunk size of 2048 tokens, an overlap of 256 tokens, and the top 7 most relevant items seems sufficient for our use-case but it might not be optimal for other tasks.
Let's review a part of RAG's answer to the user query: "How can I use AI for business strategy?"

The full answer, which has been omitted, explains to the user how AI can impact the business and provides further details. To have an idea regarding the resources which are required to run this RAG architecture have a look at the system utilization:
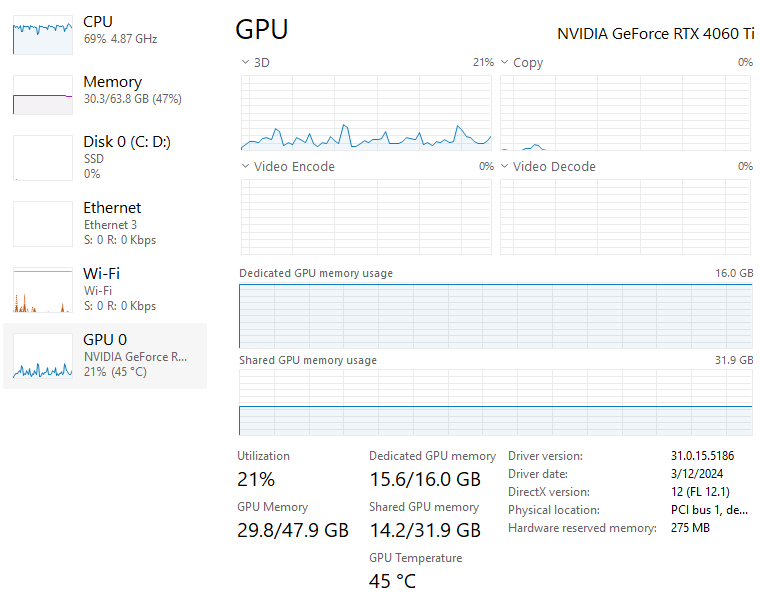
Conclusions
In this blogpost, we have reviewed Retrieval-Augmented Generation (RAG), where to use it, some potential pitfalls concerning privacy issues, and an implementation of an offline RAG architecture. RAG presents a promising advancement in natural language processing, leveraging both retrieval-based and generative models. It has already been utilized in various industries causing significant performance boosts and customer satisfaction.
On the one hand, online RAG architectures offer up-to-date information retrieval and adaptability to dynamic data. On the other hand, they may suffer from dependency on external services and privacy concerns. In contrast, offline architectures precompute and store retrieval data, providing faster response times and more controlled environments; thus, mitigating privacy concerns, but they require periodic updates to maintain relevance. Both approaches enhance the generation process by augmenting model capabilities with external knowledge, yet the choice between online and offline architectures should consider trade-offs in speed, reliability, and resource dependency based on specific application needs.
📥 Want practical AI use cases? Subscribe to stay informed.


