Concept Drift in Machine Learning: Drift Detection Mechanisms (Part II)
- May 21, 2024
- 6 min read
Updated: Jun 17, 2025
In this follow-up blogpost, we will continue investigating the topic of concept drifts. In particular, we will dive into drift detection mechanisms which focus on estimating the point of change and alert the system about this change. There is going to be a 3rd blogpost on the model adaptation techniques to overcome the problem of concept drift in the non-stationary data distribtuions, stay tuned! :)
📈 Discover how real businesses use AI to create value. Join the newsletter for practical use cases and strategic insights.
Drift detection refers to the techniques and mechanisms used to characterize and quantify concept drift by identifying change points or change time intervals. The general framework for drift detection comprises the following three stages:
Data Retrieval Stage: In this initial stage, we retrieve data chunks from the data stream. Since a single data instance does not provide sufficient information to infer the overall distribution, it is important to organize data chunks in a way that forms meaningful patterns or knowledge. Effective data chunk organization is essential in data stream analysis tasks.
Test Statistics Calculation: During this stage, we quantify the severity of the drift and develop test statistics for hypothesis testing. Measuring dissimilarity or estimating distance is considered the most challenging aspect of concept drift detection. Accurate test statistics are vital for identifying significant changes in data streams.
Hypothesis Test: In the final stage, we apply a specific hypothesis test to evaluate the statistical significance of the changes observed in Stage 2. This involves calculating the p-value. The null hypothesis posits that there is no significant difference between the old and new data, indicating no concept drift. If the null hypothesis cannot be rejected, the system continues with the current learner and proceeds with the data stream.

Data Retrieval Stage in Drift Detection
Before going into the drift detection methods, let's discuss the data retrieval stage, where data is chunked and retrieved from the stream.
Windowing techniques have gained popularity in addressing concept drift problems. These methods operate under the assumption that the most recent observations provide the most valuable information, assessing changes gradually using either a time-based or data-based window.

In this context, a 'window' is a concise memory data structure that maintains essential data or summarizes statistics related to model behavior or data distribution. Its purpose is to effectively characterize the current concept. Four main attributes characterize a window:
Specificity:
Inside the Learner: The window is specific to the learner and integrated into it.
Outside the Learner: The window is generic and can be applied to any learner.
Nature:
Data-based: The size of the window is defined by the number of instances it accommodates.
Time-based: The size of the window is defined by a time interval.
Size:
Fixed: The size is pre-determined. A small window can detect sudden drifts, while a large window can detect incremental and gradual drifts.
Variable: The size is dynamic to handle different types of drift.
Positioning Strategy: Refers to how the window evolves during monitoring. There are two main approaches:
Single Window:
Sliding Window: Periodic updates based on a fixed number of instances stored in a first-in-first-out (FIFO) structure.
Landmark Window: Stores instances from a specific time point and adjusts its size based on data stability or drift detection.
Two Windows:
Separated: One window serves as a reference and the other as the current data batch, suitable for revising offline learners and handling gradual drift.
Adjacent: Reference and current windows are kept related during data processing. Variants include fixed/fixed (useful for sudden drift), variable/fixed (useful for gradual drift), and variable/variable (useful for both sudden and gradual drift).
Overlapping: Windows share common data, beneficial for ensemble learners to intensify data usage in training individual learners.
Discontinued: Involves selecting subsets of reference data for comparison with the current window, useful for detecting local drift.
Additionally, some approaches use multiple windows, but the information provided here is sufficient to give a clear picture of the windowing techniques used in drift detection.
Mechanisms for Detecting Change in Drift Detection
We have discussed the first stage, Data Retrieval. Now, let's examine the second stage, which involves the mechanisms that allow us to detect changes. These mechanisms can be categorized into three types:
Data Distribution-Based Detectors: These detectors focus on changes in the data distribution. They identify drift by measuring dissimilarities or changes in statistical properties of the data.
Performance-Based Detectors: These detectors monitor the performance metrics of a predictive model, such as accuracy or f1score or kappa rates. Significant changes in performance can indicate potential drift.
Multiple Hypothesis-Based Detectors: These detectors use multiple hypothesis tests to evaluate whether the observed changes are statistically significant, thereby providing a more robust detection mechanism.
Data distribution-based drift detection algorithms use distance metrics to measure differences between historical and new data distributions. They trigger model updates when statistically significant dissimilarities are detected. These algorithms effectively address distribution drift and can pinpoint the time and location of drift, but they are computationally costly and require predefined historical and new data windows, often utilizing a two-sliding window strategy. To measure the distance between data distributions, common distance functions include the Hellinger distance, KL divergence, total variation, Euclidean distance, and Manhattan distance. These metrics provide mathematical expressions for both continuous and discrete variables. Such methods require a user defined threshold that triggers an alert when surpassed.
There are works that overcome this issue. For example, there is a cluster-based approach which builds clusters by using k-means on a refence window of historical data and then uses a second window to monitor the stream for changes. If the data inside the window fall outside the range of the clusters, then a drift is detected; therefore, the radius of the clusters serve as a threshold!
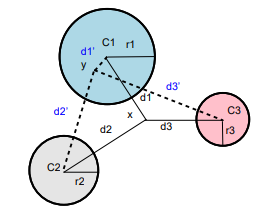
The main benefit of this approach is its applicability to both labeled and unlabeled datasets, as it relies solely on analyzing data distribution. However, when changes in data distribution do not consistently impact predictor performance, it can result in false alarms and unnecessary model updates.
Performance-based detectors track the online performance of the model. They align with the Probability Approximately Correct (PAC) learning model, where prediction error depends on example size and hypothesis space complexity. If the error rate increases despite a stationary distribution of instances, it indicates a distribution shift. One well-known method in this category is the Drift Detection Method (DDM), which uses a landmark window to monitor online model performance. It introduces a warning level threshold to mark relevant data when the error rate exceeds it. If the error rate reaches the drift level, a new learner is built using short-term memory data, replacing the old learner for further predictions. DDM is model-agnostic and versatile in its application.

These detectors efficiently manage performance changes, reducing false alarms compared to distribution-based detectors. However, they require prompt feedback, often inaccessible in reality.
Multiple hypothesis-based detectors employ techniques similar to performance and distribution-based detectors. However, they use multiple hypothesis tests to identify concept drift in distinct ways. These algorithms fall into two groups:
Parallel Multiple Hypothesis Tests:
Conduct multiple tests simultaneously to detect concept drift.
Each test examines different aspects of the data or uses different methods to identify drift.

Hierarchical Multiple Hypothesis Tests:
Utilize a multi-step verification approach.
Initially, the detection layer identifies drift using an established method.
Then, the validation layer applies an additional hypothesis test to confirm the detected drift hierarchically.

Conclusions
The dynamic nature of data streams presents a challenge for maintaining the accuracy and reliability of machine learning models over time. Drift detection mechanisms, such as data distribution-based, performance-based, and multiple hypothesis-based detectors, play a crucial role in identifying concept drifts. Such detectors are employed by model adaptation strategies to inform the models to change or adapt. We will dive into strategies for model adaptation, including informed and blind approaches in the next and final blogpost in this series of posts regarding concept drift. Stay tuned for the next post if you are interested to know the adaptation strategies for dealing with concept drifts.
📥 Want practical AI use cases? Subscribe to stay informed.
